Многие сайты на CMS Joomla в процессе проверки на соответствие стандартам и сертификатам W3C выдают множество ошибок и предупреждений. Мало того, существуют сайты, которые вообще не поддаются проверке из-за некорректной кодировки. Однозначно, рано или поздно такой ресурс проиндексируется, но авторитетности в глазах поисковиков это ему не добавит. Непонятные для заданной по умолчанию кодировки utf-8 символы, как правило, возникают в процессе верстки веб-страниц. Валидатор предназначен для поиска и отображения ошибок, все остальное зависит от сайтостроителей.
Если после очередного анализа валидности сайта Joomla система сообщает о невозможности проверки, данная статья поможет исправить возникшую проблему. И так, после текущего анализа на странице сервиса отобразилось подобное сообщение:

Устранение ошибки кодировки HTML при валидации сайта
Какие дальнейшие действия? Для начала нужно определиться, в каком месте обнаружена ошибка. Естественно об этом указывает сам сервис W3C в виде следующей подсказки:
Sorry, I am unable to validate this document because on line 927 it contained one or more bytes that I cannot interpret as utf-8 (in other words, the bytes found are not valid values in the specified Character Encoding). Please check both the content of the file and the character encoding indication.
The error was: utf8 "\xE4" does not map to Unicode
Как видите, в сообщении указана цифра 927. Хорошо, с местом определились, но как быть дальше? А дальше нужно посмотреть исходный текст страницы. То есть открыть в браузере сайт и нажать горячие клавиши Ctrl+U. В результате в новой вкладке откроется новая страница со всеми элементами HTML. Теперь нужно отыскать строку под номером 927. Напротив нее должен находиться определенный текст, в котором и допущена ошибка кодировки. Как правило, это буква кириллического алфавита. Теперь нужно скопировать отрывок текста расположенного напротив цифры 927.

Далее понадобится скачать копию сайта к себе на компьютер и воспользоваться бесплатным редактором текстов Notepad++. В открывшейся программе нужно выбрать Поиск/Найти в файлах и в строку «Найти», вставить из HTML кода страницы скопированный текст.
В моем случае это небольшой отрывок, который можно увидеть на картинке. В строке команды «Папка» необходимо вставить путь к заранее скачанной копии сайта.
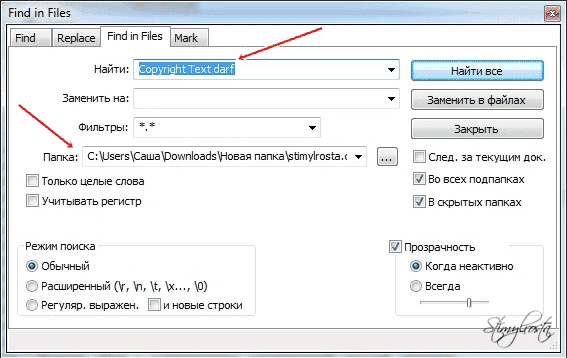
Как можно увидеть на представленном скриншоте, указанное в поисковой строке словосочетание отображается красным. Обратите внимание, слово в котором допущена ошибка – «verдndert». Достаточно убрать одну букву, и сайт будет доступен для дальнейшей проверки на соответствие стандартам валидности.
![]()
Но как узнать, в каком файле производить правку? Спешу заметить, что о месте расположения файла сообщает тот же Notepad++. Путь обозначается зеленым фоном. В итоге в моем случае нужно править файл index.php, расположенный в папке шаблона сайта. Опять же, текстовый редактор указывает и куда именно направляться - Line 250. Это говорит о том, что нужно отыскать в файле index.php строчку 250 и удалить одну буковку «д» в слове «verдndert».
После устранения определенных ошибок ваш сайт на движке Джумла опять может беспрепятственно проходить очередную полноценную проверку на валидность HTML.
Спасибо за внимание и до скорого на страницах Stimylrosta.

Обнаружили в тексте грамматическую ошибку? Пожалуйста, сообщите об этом администратору: выделите текст и нажмите сочетание горячих клавиш Ctrl+Enter